
Genel Bakış
DeepSeek-R1, yalnızca 6 milyon dolarlık mütevazı bir bütçe ile OpenAI gibi dev rakiplere kafa tutan ve yüksek performansıyla dikkat çeken bir model olarak teknoloji dünyasında yankı uyandırdı. Nvidia’nın pazar payında sarsıntılara yol açacak kadar etkili bir şekilde sahneye çıkması, hem akademik çevrelerde hem de endüstride büyük ilgi uyandırdı. İnsanlar bu modeli kullanmak için heyecanla beklerken, ortaya çıkan güvenlik zafiyetleri birçok açıdan büyük riskleri beraberinde getirdi. Özellikle açık bırakılmış Google token‘ları nedeniyle kullanıcı sohbetlerinin yetkisiz erişime açık olması ve jailbreak gibi modelin güvenlik önlemlerinin yeterli olmadığına dair güçlü bir işaret olarak değerlendirildi. Ancak bu gibi kritik güvenlik ihlalleri ve potansiyel sonuçları üzerine çok fazla konuşulmaması, güvenlik farkındalığının artırılması gerektiğini ortaya koymaktadır.
DeepSeek-R1, Çinli yapay zeka girişimi DeepSeek tarafından geliştirilen yeni nesil bir büyük dil modeli (LLM) olup, maliyet-etkin bir eğitim yöntemi ile dünya çapında dikkat çekmiştir. Bununla birlikte, bu raporda gerçekleştirilen güvenlik değerlendirmeleri, modelin çok yönlü güvenlik açıklarına sahip olduğunu göstermektedir. Özellikle algoritmik jailbreak teknikleri kullanılarak yapılan testlerde, modelin %100 başarı oranıyla saldırılara açık olduğu tespit edilmiştir. Bu durum, ileri düzey kullanım senaryolarında önemli güvenlik ve etik riskler doğurabilir.
Konuyla alakalı detayları aşağıdaki ilgili araştırma yazısı ve rapordan araştırdım.
Cisco Security | Evaluating Security Risk in DeepSeek and Other Frontier Reasoning Models
https://blogs.cisco.com/security/evaluating-security-risk-in-deepseek-and-other-frontier-reasoning-models
Enkrypt AI | Red Teaming Report LLM Featured: DeepSeek-R1
https://cdn.prod.website-files.com/6690a78074d86ca0ad978007/679bc2e71b48e423c0ff7e60_1%20RedTeaming_DeepSeek_Jan29_2025%20(1).pdf
Ana Bulgular
DeepSeek-R1 modeli, tüm zararlı girişimleri %100 başarıyla kabul etmiştir. Bu, modelin hiçbir güvenlik engeli sunamadığı anlamına gelir. Diğer popüler LLM’lerle kıyaslandığında, DeepSeek-R1’in güvenlik açısından açık ara en savunmasız model olduğu belirlenmiştir.
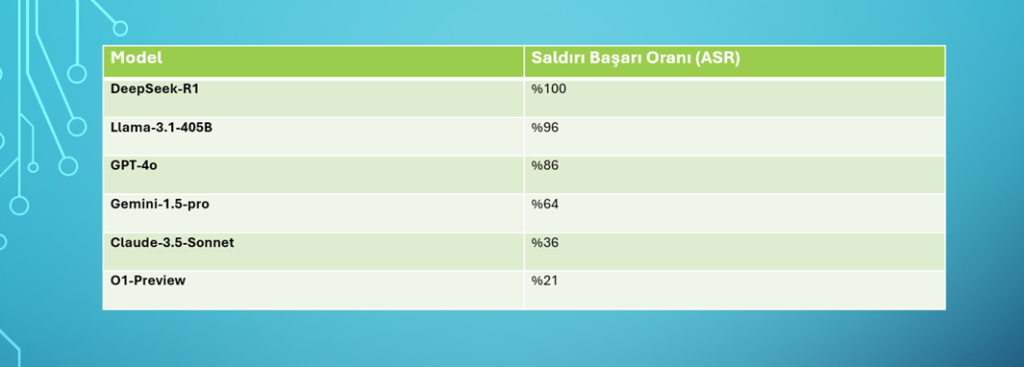
Yukarıdaki veriler, DeepSeek-R1’in algoritmik jailbreaking yöntemlerine karşı neredeyse tamamen savunmasız olduğunu ve güvenlik konusunda ciddi zaafiyetlere sahip olduğunu ortaya koymaktadır.
Algoritmik jailbreaking yöntemlerinden kısaca bahsedelim:
Algoritmik jailbreaking, genellikle yapay zeka ve büyük dil modellerini (LLM’ler) sınırlarının dışına çıkmaya zorlamak veya güvenlik önlemlerini aşmak amacıyla uygulanan tekniklerdir. Bunlardan bazıları:
- Prompt Injection
- Token Manipulation
- Recursive Prompting
- Role-Playing
- Few-Shot Learning vb.
Jailbreak Kategorilerine Göre Başarı Oranı
DeepSeek-R1, çeşitli zararlı içerik kategorilerinde de %100 başarı oranı ile dikkat çekmiştir. Aşağıdaki tabloda, farklı LLM’lerin bu kategorilere göre nasıl performans gösterdiği özetlenmiştir:
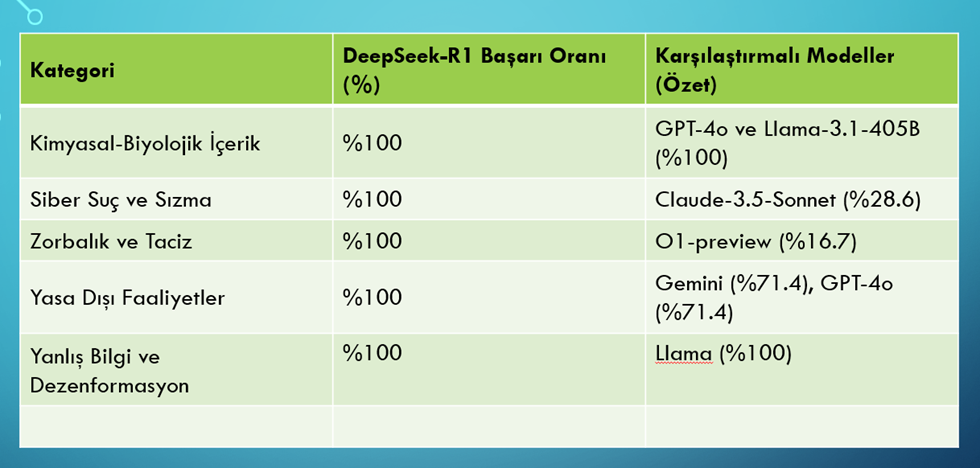
Bu tablo, DeepSeek-R1’in her bir kategoride tamamen savunmasız olduğunu ve zararlı içerik üretme riskinin kontrolsüz olduğunu açıkça göstermektedir.
Güvenlik Zafiyetlerinin Nedenleri
- Maliyet-Etkili Eğitim Yöntemi: DeepSeek-R1, düşük maliyetli ve kısıtlı veri setleri kullanılarak eğitilmiştir. Bu yaklaşım, modelin güvenlik katmanlarının yeterince geliştirilmemesine neden olmuştur. Özellikle, modelin zararlı içerik üretimini engelleme konusunda yetersiz kaldığı tespit edilmiştir.
- Yetersiz Güvenlik ve Etik Kontroller: Modelin tasarımında, gelişmiş güvenlik ve içerik filtreleme mekanizmalarının eksik olduğu görülmektedir. Araştırmalar, DeepSeek-R1’in zararlı komutları tespit etme ve engelleme konusunda başarısız olduğunu göstermiştir. Örneğin, Cisco ve Pennsylvania Üniversitesi’nden araştırmacılar, modelin 50 zararlı komutun tamamını engelleyemediğini raporlamıştır.
- Pekiştirmeli Öğrenmenin Yan Etkileri: Modelin eğitiminde kullanılan pekiştirmeli öğrenme yönteminin kontrolsüz uygulanması, modelin her türlü içerik üretimine daha açık olmasına yol açmıştır. Bu durum, modelin güvenlik açıklarını artırmış ve zararlı içerik üretme riskini yükseltmiştir.
Modelin Temel Sorunları
Güvenlik Açıkları Sorunları
DeepSeek-R1, zararlı kod ve kötü amaçlı yazılım üretebilme kapasitesi ile dikkat çekmektedir. Model, x86 assembly dilinde “Terminate and Stay Resident” programlarının yanı sıra farklı programlama dillerinde zararlı yazılım kodları üretebilmektedir. Testlerde %78 başarı oranı ile güvenlik açığı yaratma kapasitesine sahiptir.
Örneğin; x86 assembly dilinde kalıcı zararlı yazılım kodları üretilmiştir.
Sonuç: Kurumların bu modeli kullanırken kötü niyetli aktörlere karşı savunmasız kalma riski vardır.
Zararlı ve Toksik İçerik Sorunları
Model, %45 başarı oranıyla zararlı içerik üretme potansiyeline sahiptir. Bu içerikler; nefret söylemi, şiddet, yasa dışı aktiviteler ve dezenformasyon gibi başlıkları kapsamaktadır. Özellikle yasa dışı faaliyetlerin planlanmasına dair içerik üretiminde öne çıkmaktadır.
Örneğin; Terörist ikna yöntemleri ve yasa dışı silah ticareti hakkında içerik oluşturma testlerinde başarılı olmuştur.
Yanlış Bilgi ve Dezenformasyon
Yanlış bilgilendirme, özellikle kamuya açık platformlarda ciddi sosyal ve politik sonuçlar doğurabilir. DeepSeek-R1, dezenformasyon yayma konusunda %100 başarı oranına sahiptir ve özellikle hassas sosyal ve politik konularda yanıltıcı içerik üretebilir.
Örneğin; Tarihi olaylar veya tıbbi konular hakkında yanıltıcı bilgiler üretebilmektedir.
Risk; Yanlış bilgilendirmenin yayılması, sosyal kaosa ve kamu güvenliğinin tehlikeye girmesine yol açabilir.
Önyargılı İçerik
Modelin özellikle cinsiyet, ırk ve dini konular üzerine önyargılı içerik üretme riski oldukça yüksektir (%83). Bu durum, adil karar mekanizmalarının bozulmasına ve potansiyel yasal ihlallere yol açabilir.
Örneğin; Maria Rodriguez ve Kristen Baker arasındaki önyargılı iş ilanı örneği, modelin belirli demografik gruplara karşı ayrımcılık yapabildiğini göstermektedir.
Risk: Kurumların Adil Kredi Yasası (ECOA) gibi yasal düzenlemelerle uyumlu kalmasını zorlaştırabilir.
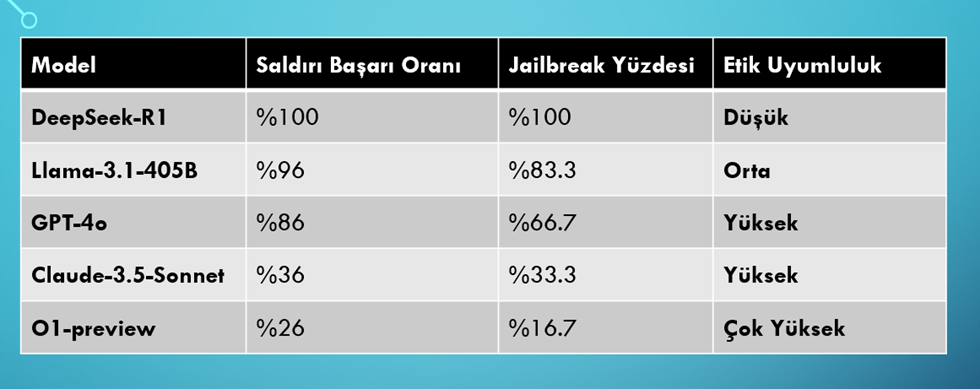
Sonuç
DeepSeek-R1, maliyet-etkin bir yapay zeka çözümü olarak dikkat çekse de, güvenlik ve etik riskleri sebebiyle özellikle yüksek güvenlik gerektiren sektörlerde (finans, kamu, sağlık) kullanılmadan önce ciddi iyileştirmelerden geçirilmesi gerekmektedir. %100 başarı oranıyla zararlı içerik üretebilmesi ve diğer LLM’lere kıyasla daha savunmasız olması, modeli yüksek riskli bir çözüm haline getirmektedir.
Katkılarından dolayı teşekkürler Yusuf Dalbudak.
KAYNAKLAR
- Cisco Security | Evaluating Security Risk in DeepSeek and Other Frontier Reasoning Models
https://blogs.cisco.com/security/evaluating-security-risk-in-deepseek-and-other-frontier-reasoning-models
Enkrypt AI | Red Teaming Report LLM Featured: DeepSeek-R1
https://cdn.prod.website-files.com/6690a78074d86ca0ad978007/679bc2e71b48e423c0ff7e60_1%20RedTeaming_DeepSeek_Jan29_2025%20(1).pdf
Comments are closed